Classical:
Google, DuckDuckGo
Mobile phone search
IDE auto-completion
Discuss inverted index technology and fundamentals
You can read the speaker notes by pressing s
Consulting Software Engineer, Red Hat
Chief Architect
Open Source coder:
Hibernate {ORM,OGM,Search,Validator}
Debezium, Infinispan, …
Podcasts: Les Cast Codeurs
Why
B-tree vs inverted index
Building & using an inverted index
Indexing
Querying
Scoring
Physical representation
Classical:
Google, DuckDuckGo
Mobile phone search
IDE auto-completion
Less classical
geolocation
suggestion
faceting
more like this / classification
machine learning
SELECT * FROM Speakers s WHERE s.bio = 'Open Source'How is the index built?
Self-balancing tree data stucture
Search, insert and delete in O(log n)
Good when access time >> process time
Replace numbers in the example with letters for text.
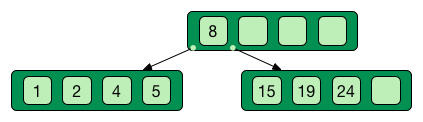
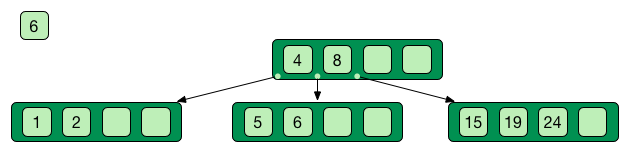
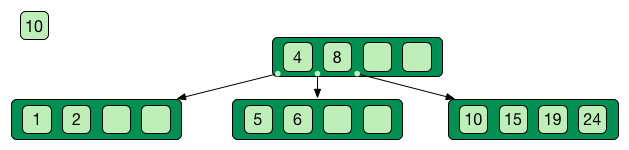
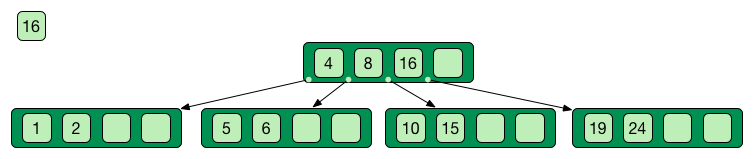
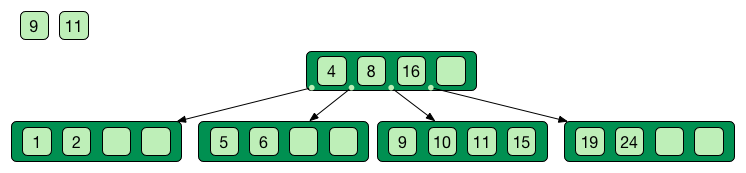


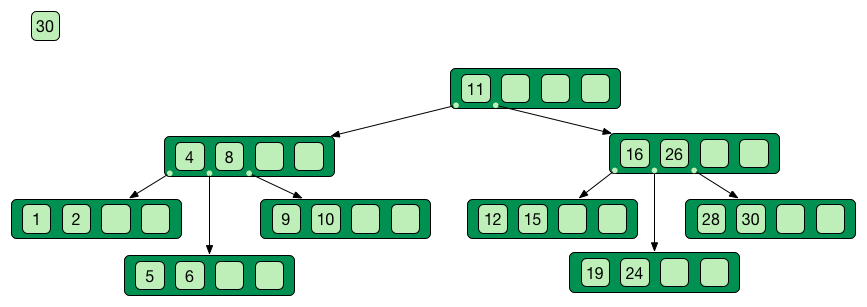
Only keys in the non leaf nodes
Leaf nodes linked with one another for efficient ascending reading
Data can be just pointer to the real data

Not only is that terrible in general, but you just KNOW Billy’s going to open the root present first, and then everyone will have to wait while the heap is rebuilt.
SELECT * FROM Speakers s WHERE s.bio LIKE 'Open Source%'With like we can have more text after
Still using indices
SELECT * FROM Speakers s WHERE s.bio LIKE '%Open Source%'Find word anywhere in the text
Table or index scan :(
SELECT * FROM Speakers s WHERE
s.bio LIKE '%open source%'
OR s.bio LIKE '%Open Source%'
OR s.bio LIKE '%opan surce%'Can’t anticipate the casing
Can’t anticipate all typos
SELECT * FROM Speakers s WHERE
s.bio LIKE '%source open%'
OR s.bio LIKE '%source%'
OR s.bio LIKE '%open%'
ORDER BY best??Words could be in any order
I want the most interesting result first
Some have powerful indexing techniques
Some even full-text related
Tend to have less flexibility than dedicated inverted index tools
Let’s not index column values but words
Let’s not query values but words
doc1: I am your father Luke
doc2: Yes he is your father
doc3: I am gonna make him an offer he can not refuse.
doc4: I love the smell of napalm in the morning.
doc5: One morning I shot an elephant in my pajamas. How he got in my pajamas, I do not know.
| word | documents |
|---|---|
am | 1,3 |
an | 3,5 |
can | 3 |
do | 5 |
elephant | 5 |
father | 1,2 |
gonna | 3 |
got | 5 |
he | 2,3,5 |
him | 3 |
how | 5 |
i | 1,3,4,5 |
in | 4,5 |
is | 2 |
know | 5 |
love | 4 |
luke | 1 |
make | 3 |
morning | 4,5 |
my | 5 |
not | 3,5 |
napalm | 4 |
of | 4 |
offer | 3 |
one | 5 |
pajamas | 5 |
refuse | 3 |
shot | 5 |
smell | 4 |
the | 4 |
yes | 2 |
your | 1,2 |
query: father napalm
Apply the same word splitting logic
Matching documents: 1, 2 and 4
| word | documents |
|---|---|
father | 1,2 |
napalm | 4 |
Analyzers
pre-tokenization
tokenization
filter
Apply the same logic to both document and query content
Each token is the entry in the inverted index pointing to documents
Remove unnecessary characters
e.g. remove HTML tags
<p>This is <strong>awesome</strong>.</p>
This is awesome.Split sentence into words called tokens
Split at spaces, dots and other punctuations (with exceptions)
aujourd’hui, A.B.C., and many other rules
One tokenizer per language, but many languages are similar
Didyouknowwritingtextsinwordsseparatedbyspaceisnotthatold
itstartedinthemiddleage
Itwasnotaproblemaspeoplewerereadingoutloudwrittentext
Infactsplittingwordswasaninventionnecessary
becausemonksshouldremainsilentandlatinwasnolongertheirnativetongue
Operate on the stream of tokens
Change, remove or even add tokens
lowercase, stopwords
Sentence: This is AWESOME Peter!
Tokens: |This|is|AWESOME|Peter|
stopwords: |AWESOME|Peter|
lowercase: |awesome|peter|When the text mentions a "car" but the research is about "automobile" or "vehicle"
We need a synonym dictionary
Put all synonyms in the index for each word
Use a reference synonym ("automobile" for "car", "compact", "auto", "S.U.V."…)
Index normally, use synonyms when building the query
education, educates, educated, …
That would make for lots of synonyms…
Let’s use a stemming algorithm
Porter stemming algorithm
Snowball grammar
French algorithm explained
Index/query the stem when the word is found
| word | stem |
|---|---|
main | main |
mains | main |
maintenaient | mainten |
maintenait | mainten |
maintenant | mainten |
maintenir | mainten |
maintenue | mainten |
maintien | maintien |
People make mistakes
In the text or in the query
They make thaipo and other mystakes
Same logic as stemming, convert word into phonetic approximation
Soundex, RefinedSoundex, Metaphone, DoubleMetaphone
Split a word into a sliding window of n characters
Index each n-gram
// building a 3 gram
mystake: mys yst sta tak ake
mistake: mis ist sta tak akeLow n means more false positives
High n means less forgiving
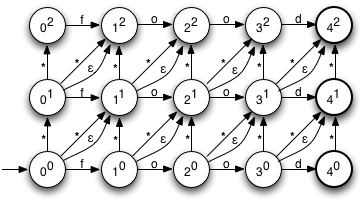
Based on Damerau-Levenshtein distance
insert, update, delete and transposition
Pure query time operation
Compute distance between word and all words in index
or
Compute a distance state machine for word
Use it to check specific terms in the index
ne: n consumed chars, e errors
horizontal: unmodified chars
* vertical: addition
* diagonal: substitution
ε diagonal: deletion
Apply different indexing approach for same data
It’s term query all the way down!
All queries (synonyms, phonetic, n-gram, fuzzy) are a (set of) term queries
Term, wildcard, prefix, fuzzy, phrase, range, boolean, all, spatial, more like this, spell checking
Find exact sentences
or find words near one another (sloppiness)
"Laurel and Hardy"PhraseQuery uses positional information
Shingles uses n-grams but per tokens not per chars

Found results but in random order…
We want the most relevant results first
This is relative
Several approaches, none perfect
How often does the term appear in this document?
More is better
How often does the term appear in all documents in the collection?
Common words are less important
How long is the field?
Long documents would be favored otherwise
If document contains multiple terms, it’s a better fit.
Boolean model
Vector space model
Term Frequency / Inverted Document Frequency
Boosting fields
Positional (phrase query) or similarity (fuzzy) information
Feedback function (external or internal)
Okapi BM25
Your custom scoring function (or a tweak of)
A Lucene example
Search engine library
Used by many, including
Solr
Elasticsearch
Hibernate Search
When you need write throughput
B-tree requires lots of updates in place
Sequential reads are much faster than random reads
on disk
kinda also in memory (L1-3 caches)
Append operations in a file
Reading requires reading all the log
Per batch of writes, create a file storing the sorted key/value pairs
On read, check for the key on each file
Regularly merge files together (e.g. make bigger files)
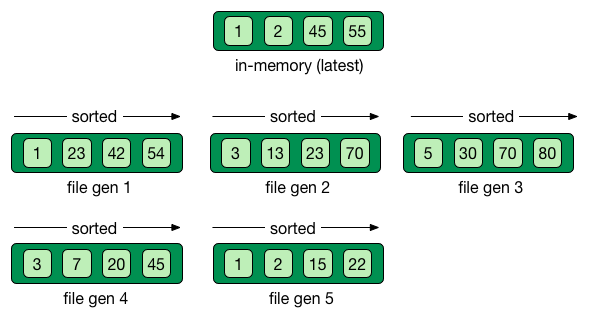
Immutable (lock-free) and file cache friendly
Fast on write, decent on read
Sequential read/write friendly
Read time decays with number of files ⇒ merge
Page index in memory
Bloom filter
Level-based compaction
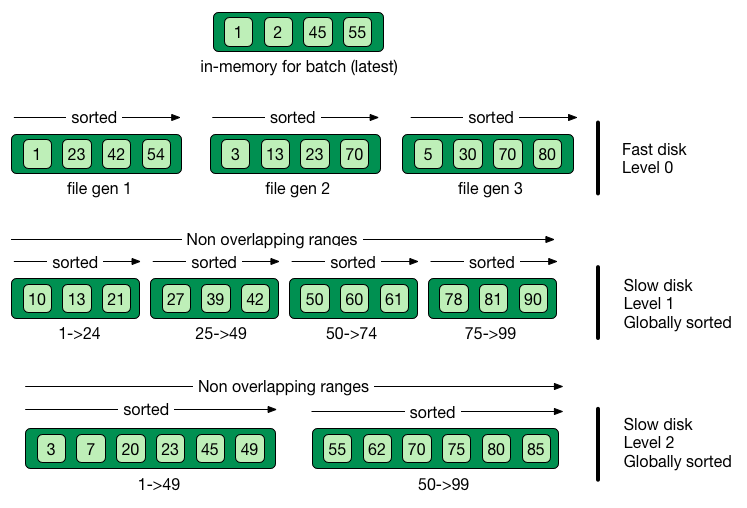
Limit the number of files to read
One file per level to be consulted
Compact to the higher levels
Each file per level has non overlapping key ranges
LSM
Everything is computed upfront
Each segment is a mini index
Denormalize differently depending on access pattern
term index (like a ToC for the dictionary)
term dictionary (points to posting list offset)
posting list (list of matching document id per term)
stored field index (sparse doc id + offset)
stored field data (list of field values per document id)
deleted documents
Term index provides offset to the dictionary
Based on finite state transducers
Gives one ordinal per prefix
We know where to look in the term dictionary
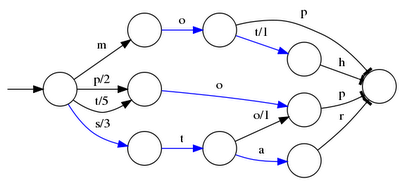
FST for mop, moth, pop, star, stop and top
mop=0
moth=1
pop=2
star=3
stop=4
top=5From a given offset (& prefix)
Sorted list of suffixes
For each, frequency and offset to posting list
[prefix=top]
_null_, freq=27, offset=234
ography, freq=1, offset=298
ology, freq=6, offset=306
onyms, freq=1, offset=323List of document ids
Variable int encoding
Encoded as delta of ids (good for variable int encoding)
4,6,9,30,33,39,45 => 4,2,3,23,3,6,6PForDelta encoding
Bigger in size but less CPU branch miss prediction
Also pulse optimization for frequency=1
Stored field index in memory doc id + offset for every 16k of data
Stored value stored as bocks of 16k and compressed
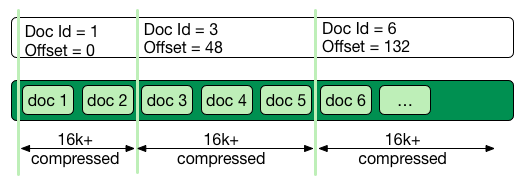
You said segments are immutable
What about deleted documents?
Deleted document file
1 bit per doc
sparse list of cleared docs

2 disk seeks per field search (binary search)
1 disk seek per doc for stored fields
But things likely fit in file system cache
Warning: this is a simplified view :)
Columnar storage
Called doc values
Used for aggregation or sorting or faceting
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
XKCD images are licensed under Creative Commons Attribution-NonCommercial 2.5 License.
A couple of drawings are copyright of their respective author (linked in the references).
B-tree and LSM
Analyzers
snowballstem.org
Scoring
Query
Lucene file and memory structure
http://stackoverflow.com/questions/2602253/how-does-lucene-index-documents
https://web.archive.org/web/20130904073403/http://www.ibm.com/developerworks/library/wa-lucene/
http://www.research.ibm.com/haifa/Workshops/ir2005/papers/DougCutting-Haifa05.pdf
http://blog.mikemccandless.com/2010/12/using-finite-state-transducers-in.html